생성형 AI의 등장은 놀랍다. GPT나 Gemini 같은 거대 언어 모델(LLM)은 사람처럼 대화하고, 글을 쓰고, 아이디어를 제공한다. 하지만 이 똑똑한 AI에게 업무를 맡겨본 사람이라면 누구나 한 번쯤은 고개를 갸우뚱한 경험이 있을 것이다. AI가 너무나도 그럴듯하게, 하지만 사실이 아닌 정보를 말하는 순간이다.
이것이 바로 LLM의 가장 큰 약점, 환각(Hallucination)이다. 오늘은 이 문제를 해결하고, AI를 단순한 '창의적인 대화 상대'에서 '신뢰할 수 있는 전문가'로 만드는 핵심 기술, RAG(Retrieval-Augmented Generation)에 대해 이야기한다.
똑똑한 AI의 세 가지 그림자
RAG를 이해하기 전에, 왜 RAG가 필요한지 먼저 알아야 한다. LLM은 그 자체로 몇 가지 명백한 한계를 가진다.
- 환각 (Hallucination): LLM은 학습한 데이터를 기반으로 가장 그럴듯한 답변을 '생성'한다. 정보가 부족해도 어떻게든 말을 만들어내기 때문에, 그럴듯한 거짓말을 할 위험이 항상 존재한다.
- 지식의 단절 (Knowledge Cut-off): 모델은 특정 시점까지의 데이터로만 훈련된다. 2025년 최신 제품 정보나 바뀐 회사 정책을 물어보면 알지 못한다.
- 출처의 부재: LLM은 답변의 근거를 명확히 제시하지 못한다. "그 정보는 어디서 확인하나요?"라는 질문에 답할 수 없다. 기업 환경에서는 이는 신뢰도에 치명적인 문제이다.
이 문제들은 AI를 실제 비즈니스에 도입하는 것을 가로막는 가장 큰 장벽이다.
AI에게 '오픈북 시험'을 허락하다
RAG(Retrieval-Augmented Generation), 우리말로는 '검색 증강 생성'이다.
이 기술을 가장 쉽게 비유하자면, '똑똑한 학생(LLM)에게 오픈북 시험을 보게 하는 것'이다.
아무리 똑똑한 학생이라도 세상의 모든 책을 외울 수는 없다. 하지만 참고할 책(신뢰할 수 있는 데이터)을 옆에 두고 시험을 본다면, 훨씬 정확하고 근거 있는 답안을 작성할 수 있다. RAG는 바로 이 원리를 적용한 것이다.
RAG의 작동 방식은 놀랍도록 직관적이며, 세 단계로 이루어진다.
- 검색 (Retrieval): AI는 사용자 질문에 바로 답하지 않는다. 먼저 질문과 가장 관련 있는 정보를 회사의 내부 데이터베이스, 매뉴얼, 정책 문서 등 신뢰할 수 있는 '책'에서 찾아본다.
- 증강 (Augmentation): 그렇게 찾아낸 정확한 정보를 사용자의 원래 질문과 함께 LLM에게 전달한다. 즉, LLM에게 '시험 문제'와 함께 '참고 자료'를 함께 주는 것이다.
- 생성 (Generation): LLM은 방금 전달받은 '참고 자료'에만 기반하여 답변을 생성한다. 더 이상 자신의 기억에만 의존하지 않으므로, 거짓말을 할 이유가 사라진다.
마법은 어떻게 일어나는가?
'오픈북'에서 원하는 페이지를 순식간에 찾아내는 과정은 구체적인 기술 흐름을 따른다.
이 과정은 크게 '사전 준비'와 '실시간 검색' 두 단계로 나뉜다.
[사전 준비] 지식 라이브러리 구축 - 고객을 만나기 전, AI가 참고할 '책'들을 미리 정리해두는 과정이다.
① 데이터 벡터화 (Embedding): 회사의 모든 문서(매뉴얼, FAQ 등)를 의미 있는 단락으로 나눈다. 그리고 '임베딩 모델'이라는 특별한 번역기를 통해 각 단락의 '의미'를 컴퓨터가 이해할 수 있는 숫자 좌표, 즉 벡터(Vector)로 변환한다. 의미가 비슷한 단락은 이 좌표 공간에서 서로 가까운 위치에 놓이게 된다.
② 벡터 DB 저장 (Indexing): 변환된 벡터 데이터들을 '벡터 데이터베이스(Vector Database)'라는 특수한 도서관에 차곡차곡 저장하고 색인을 생성한다. 이 DB는 특정 좌표와 가장 가까운 좌표들을 초고속으로 찾는 데 특화되어 있다.
[실시간] 정확한 정보 검색 및 답변 - 실제 고객의 질문이 들어왔을 때 일어나는 과정이다.
③ 질문 벡터화 (Query Embedding): 고객의 질문 역시 [사전 준비]에서 사용했던 것과 동일한 '임베딩 모델'을 통해 벡터 좌표로 변환된다.
④ 유사도 검색 (Similarity Search): 시스템은 이 질문 벡터를 벡터 DB에 보내 "이 좌표와 가장 가까운(의미가 가장 유사한) 문서 단락 Top 3를 찾아줘!"라고 요청한다. 이것이 RAG의 핵심적인 검색(Retrieval) 과정이다.
⑤ 프롬프트 증강 및 생성 (Augment & Generate): 검색된 최상위 문서 단락들을 질문과 함께 LLM에게 전달한다. LLM은 이 '참고 자료'에만 기반하여 정확하고 근거 있는 답변을 **생성(Generation)**한다.
이 전체 과정을 한눈에 볼 수 있도록 시각화하면 아래와 같다.
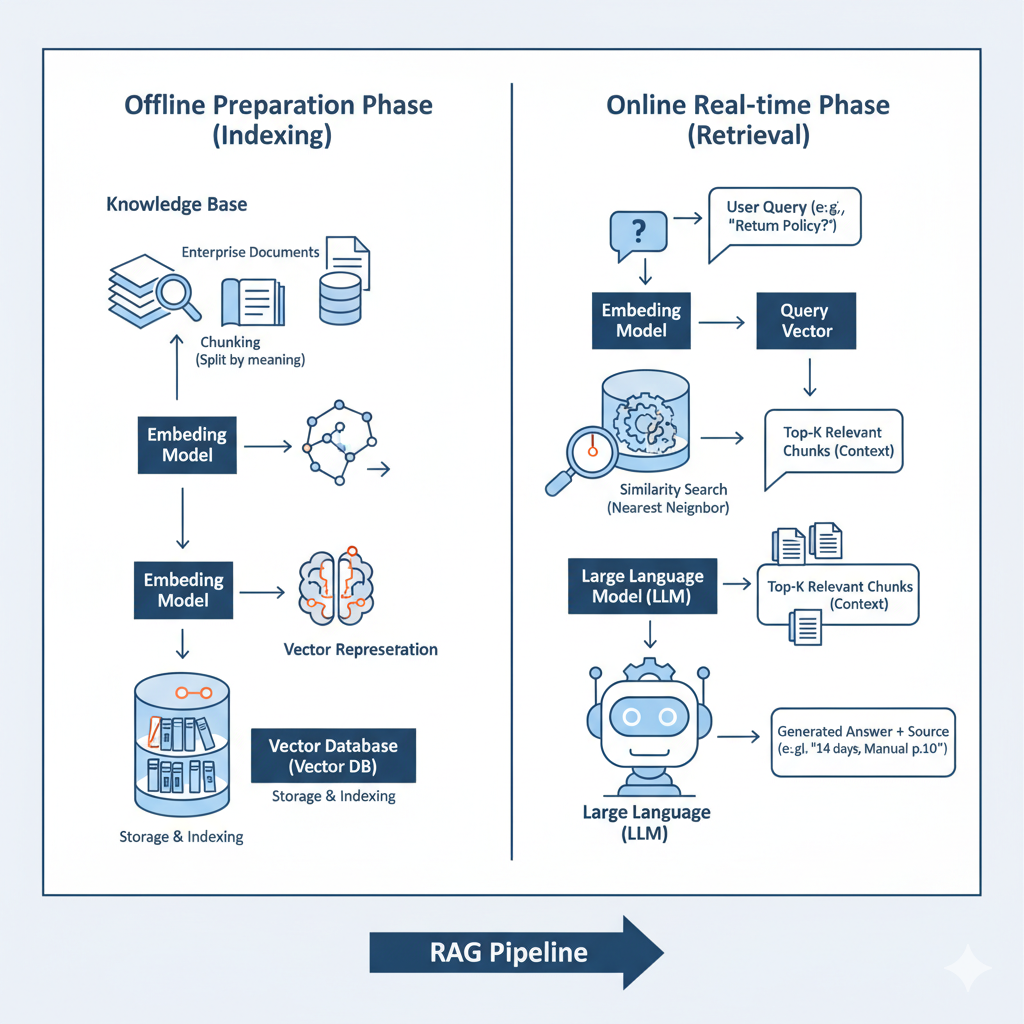
이 전체 흐름 덕분에 AI는 스스로 추측하는 대신, 검증된 데이터를 기반으로 답변하게 된다. 벡터 데이터의 조회를 예로 설명하였을 뿐, 이 단계에선 다양한 정형 데이터를 가져와서도 구성이 가능하다. 때론 이러한 정형데이터 수집하여 조회하는 데이터가 더 강력한 실시간 상세 정보제공에 용이할 수 있다. (ex. Text-to-SQL 및 Hybrid Search)
RAG가 만드는 실질적인 차이
AI 상담원 시나리오를 생각해보자.
고객: "새로 나온 스마트 에어프라이어 반품 규정이 어떻게 되나요?"
ㄱ. "보통 가전제품은 7일 이내에 반품이 가능할 것이다. 자세한 사항은 매장에 문의해달라."
ㄴ. "네, '스마트 에어프라이어' 제품은 구매 후 14일 이내, 제품 박스와 구성품이 모두 있는 경우 반품이 가능하다. 이 내용은 당사의 반품 정책 문서 3.1항에서 확인할 수 있다."
근거가 빈약하고 부정확하고 무책임한 답변, 출처가 분명하고 질문자의 프롬프트에 최대한 상응하는 답변
두 답변의 차이가 바로 품질의 차이로 이어진다.
RAG는 AI의 답변을 사실에 기반(Fact-based)하게 만들고, 최신 정보(Up-to-date)를 반영하며, 출처 추적(Traceable)이 가능하게 한다.
이미 우리 곁에 있는 RAG
"어? 그런데 내가 쓰는 ChatGPT나 Gemini 각 파생 서비스들은 최신 정보도 알려주고, 출처도 보여주던데?"라고 생각할 수 있다. 정확하다. 우리가 사용하는 AI 서비스들은 순수한 LLM이 아니다. 이 서비스들은 LLM이라는 엔진에 실시간 웹 검색이라는 RAG와 유사한 메커니즘을 결합한 '완성된 애플리케이션'이다.
기업이 AICC와 같은 시스템을 구축하는 것도 마찬가지이다. 인터넷이 아닌 우리 회사의 내부 데이터를 '오픈북'으로 삼는 RAG 시스템을 구축하여, 우리 비즈니스에 특화된 전문가 AI를 만드는 것이다.
RAG는 AI를 환상 속 기술이 아닌, 실제 비즈니스 문제를 해결하는 신뢰할 수 있는 도구로 만들어주는 첫 번째 관문이다.

